Unicornを使ったマルウェア解析の効率化
UnicornはBlack Hat USA 2015で発表および公開された、QEMUをベースとしたCPUエミュレータフレームワークです。
GitHub – unicorn-engine/unicorn: Unicorn CPU emulator framework (ARM, AArch64, M68K, Mips, Sparc, PowerPC, RiscV, S390x, TriCore, X86)
https://github.com/unicorn-engine/unicorn
マルウェア解析やファジングといった様々な用途で活用されており、後述する通り他のエミュレータフレームワークと比較しても優位な点が複数存在するため、多くのバイナリ解析者によって愛用されています。この記事ではUnicornの基本について解説するとともに、マルウェア解析における活用例について紹介します。
Unicornの特徴
このセクションではUnicornの特徴的な要素を3つ紹介します。
マルチアーキテクチャ対応
Unicornはこの記事の執筆時点 (2025年7月) で10種のアーキテクチャのエミュレーションに対応しています。同じくCPUコードのエミュレーションに対応しているMiasmは5種しか対応しておらず1、これは他のエミュレータフレームワークと比較しても非常に優位な点だといえます。
| ARM | ARM64 (ARMv8) | M68K | MIPS | PowerPC |
| RISCV | SPARC | S390X | TriCore | X86 (16, 32, 64ビット) |
これらのアーキテクチャのコード実行環境が用意できなかったとしても、Unicornを使用すればコードをエミュレートして動作を確認することができます。
軽量
UnicornはシステムコールといったOSのコンテキストを考慮しないため、他のバイナリ解析フレームワークと比較しても軽量であることが知られています。もっと高いレイヤー (入出力のハンドリングや実行ファイル単位) のエミュレーションを行いたい場合はUnicornベースのエミュレータフレームワークであるQiling Frameworkなどを採用するとよいでしょう。
豊富なバインディング
UnicornではPythonはもちろん、C、Rust、.NET Frameworkなどといった豊富なバインディングが公式で提供されています。
最近ではIDA SDKのRustバインディング2なども登場しているため、工夫すればIDAとRustのみでUnicornを使ったマルウェア解析の自動化プログラムを開発することも可能です。
Unicorn × マルウェア解析
仮想的にCPUコードを実行できるという特性を利用して、マルウェア解析者はしばしば、マルウェア内の文字列やデータを復号したり、コントロールフローに影響する難読化を解除するためにUnicornを使用します。すでに発表されてから約10年経過しており、多くの活用例が一般に公開されているため初学者にとっても親しみやすいフレームワークだというのもUnicornの長所の1つだと言えるでしょう。この記事もそのうちの1つだと言えますが、参考までにUnicornをマルウェア解析に利用している例をいくつか、以下に示します。
- Decrypting BazarLoader strings with a Unicorn (Jason Reaves)
- Resolving Stack Strings with Capstone Disassembler & Unicorn in Python (0ffset Traning Solutions)
- ADVDeobfuscator.py (strazzere)
Unicorn 101
Unicornのインストール方法はソースコードからのコンパイルやソフトウェアリポジトリの利用など複数ありますが、この記事では最も簡単な pip を利用したインストール方法を紹介します。 pip はPythonのパッケージ管理システムであり、 pip からUnicornをインストールすることでUnicornのPythonバインディングも併せてインストールされます3。
pip install unicornCode language: plaintext (plaintext)Unicornが正しくインストールできているか、下記のPythonスクリプトを実行して確認しましょう。
from unicorn import *
from unicorn.x86_const import *
# MOV EAX,DEADBEEF
# INC EBX
code = bytes.fromhex('B8 EF BE AD DE 43')
# Initialize Unicorn to emulate 32-bit code of x86
uc = Uc(UC_ARCH_X86, UC_MODE_32)
# Map memory region and write the code
code_base = 0x00000000
code_size = 0x00100000
uc.mem_map(code_base, code_size, UC_PROT_ALL)
uc.mem_write(code_base, b"\x00" * code_size)
uc.mem_write(code_base, code)
code_end = code_base + len(code)
# Write value to EBX register
uc.reg_write(UC_X86_REG_EBX, 0x1000)
# Start emulation
uc.emu_start(code_base, code_end, timeout=0, count=0)
# Read and output value in EAX / EBX register
print(f'EAX = {hex(uc.reg_read(UC_X86_REG_EAX))}')
print(f'EBX = {hex(uc.reg_read(UC_X86_REG_EBX))}')
Code language: Python (python)Unicornが正しく動作していれば、以下のような実行結果が出力されるはずです。
EAX = 0xdeadbeef
EBX = 0x1001ここからは、このPythonスクリプト内のコードがどのような意味を持つのか解説します。
まず1-2行目では、UnicornのAPIにアクセスするために必要なモジュールをインポートしています。ここでモジュール (unicorn) のほかに unicorn.x86_const というサブモジュールをインポートしていますが、これにはx86コードのエミュレーションに必要な定数値が含まれており、以降のコードを簡略化するためにここでインポートしています。
from unicorn import *
from unicorn.x86_const import *Code language: Python (python)6行目では、Unicornがエミュレーションするコードを変数 code に格納しています。今回はEAXレジスタに値 0xDEADBEEF を格納し、EBXレジスタの値をインクリメントするx86 (32ビット) コードを用意しました。
# MOV EAX,DEADBEEF
# INC EBX
code = bytes.fromhex('B8 EF BE AD DE 43')Code language: Python (python)次に9行目では、x86 (32ビット) のコードを実行できるように、Unicornを初期化しています。ここでは2つの定数 UC_ARCH_X86 と UC_MODE_32 を初期化時の引数として渡していますが、UC_ARCH_X86 と UC_MODE_64 を渡すことでx86 (64ビット) コードを、 UC_ARCH_ARM と UC_MODE_THUMB を渡すことでARM Thumbモードのコードをエミュレートすることができます。
# Initialize Unicorn to emulate 32-bit code of x86
uc = Uc(UC_ARCH_X86, UC_MODE_32)Code language: Python (python)12行目-17行目では、コード領域をマッピング (uc.mem_map) して、そこに5行目で定義したコードを書き込んで (uc.mem_write) います。今回はコード領域のベースアドレスを0x00000000、サイズを0x00100000として、マップした領域をゼロフィルした上で変数 code 内のコードを書き込んでいます。このように、Unicornではスタック領域やコード領域をユーザーがマッピングして制御する必要があります。
# Map memory region and write the code
code_base = 0x00000000
code_size = 0x00100000
uc.mem_map(code_base, code_size, UC_PROT_ALL)
uc.mem_write(code_base, b"\x00" * code_size)
uc.mem_write(code_base, code)Code language: Python (python)20行目では、EBXレジスタに初期値0x1000を設定しています。EBXレジスタの値をインクリメントするコードがエミュレーション対象となっているため、エミュレーションが正常に実行できた場合、最終的にEBXレジスタには値0x1001が格納されているはずです。
# Write value to EBX register
uc.reg_write(UC_X86_REG_EBX, 0x1000)Code language: Python (python)23行目では、Unicornによるエミュレーションを実行しています。ここではエミュレート対象のコードの開始アドレスおよび終了アドレスを指定する必要があります。今回の実装では、開始アドレスにはコード領域の先頭を、終了アドレスには先頭アドレスにコードの長さを足したものを指定しています。
# Start emulation
uc.emu_start(code_base, code_base + len(code), timeout=0, count=0)Code language: Python (python)最後に26行目-27行目では、EAXレジスタおよびEBXレジスタの値を読み取って print 関数で出力しています。
# Read and output value in EAX / EBX register
print(f'EAX = {hex(uc.reg_read(UC_X86_REG_EAX))}')
print(f'EBX = {hex(uc.reg_read(UC_X86_REG_EBX))}')Code language: Python (python)API Hashingの解析
API Hashingとは、API関数名やDLLファイル名を任意のアルゴリズムでハッシュ化した状態で保持し、ハッシュ値をもとに動的にAPI関数のアドレスを取得して呼び出す攻撃手法です。

このセクションでは TorNetとPureHVNCを実行する新種のローダーの調査 にて取り上げたローダーの解析でのUnicornの活用例を紹介します。当該ローダーでは、MurmurHash2と呼ばれるアルゴリズムに独自の変更を加えたアルゴリズムを使って、ハッシュ値をもとにAPI関数を呼び出すAPI Hashingと呼ばれるテクニックが実装されていました。

API Hashingが実装されたマルウェアを静的解析するには、基本的にハッシュアルゴリズムの実装を入手することが必要不可欠です。この際、独自のアルゴリズムを利用していたり、既存のアルゴリズムがカスタマイズされていたりすると、静的解析およびアルゴリズムの実装に時間がかかってしまいます。そこで、マルウェアのコードのうちハッシュ値を算出する処理をUnicornにエミュレーションさせることで、解析者がハッシュアルゴリズムを実装することなくAPI関数名をもとにハッシュ値を算出して、API Hashingの解析に利用することが可能です。
ハッシュ算出処理の特定
まずはUnicornにエミュレートさせるコードの範囲を決めなくてはいけません。多くの場合、API Hashingにおけるハッシュ値を算出する処理は独立した関数内に存在するため、ハッシュ値を算出する関数を見つけて、その関数の開始アドレスから終了アドレスまでをエミュレート対象とします。しかし、今回のローダーではハッシュ値の算出処理の前後に無関係な処理を含んでいたため、実際にハッシュ値を算出しているコードの範囲を特定する必要がありました。

今回のケースでは、ローダーのオフセット0x970Dから0x991Eまでの範囲のコードがハッシュ算出処理となっていました。
.text:1007030D C7 45 A0 95 E9 D1 5B mov [ebp+var_60], 5BD1E995h
.text:10070314 C7 45 94 18 00 00 00 mov [ebp+var_6C], 18h
.text:1007031B 8B 45 0C mov eax, [ebp+a2_strlen]
.text:1007031E 89 45 88 mov [ebp+var_78], eax
.text:10070321 8D 45 B8 lea eax, [ebp+string]
.text:10070324 89 85 7C FF FF FF mov [ebp+var_84], eax
.text:1007032A 8B 45 10 mov eax, [ebp+a3_seedval]
.text:1007032D 89 85 70 FF FF FF mov [ebp+var_90], eax
<snip>
.text:100704F9 69 85 70 FF FF FF 95 imul eax, [ebp+var_90], 5BD1E995h
.text:100704F9 E9 D1 5B
.text:10070503 89 85 70 FF FF FF mov [ebp+var_90], eax
.text:10070509 8B 85 70 FF FF FF mov eax, [ebp+var_90]
.text:1007050F C1 E8 0F shr eax, 0Fh
.text:10070512 33 85 70 FF FF FF xor eax, [ebp+var_90]
.text:10070518 89 85 70 FF FF FF mov [ebp+var_90], eax
.text:1007051E 8B 85 70 FF FF FF mov eax, [ebp+var_90] ; Storing calculated hash value to EAX registerCode language: plaintext (plaintext)エミュレーションの実行
逆アセンブル結果を見ればわかる通り、このコードはレジスタやスタック上のローカル変数を参照することでハッシュ化する文字列や長さを取得しています。そのため、エミュレーションを実行する前にレジスタやスタックに適切な値 (データ) を書き込む必要があります。
まずはスタック領域のマッピングを実施します。以下のコードでは、コード領域のマッピング時と同様にサイズ0x00100000のメモリ領域をマッピングしてスタック領域として利用しています。この時、誤ってコード領域内のアドレスをスタック領域のベースアドレス (開始アドレス) として指定したり、スタックのサイズが不十分だったりするとエミュレーションに失敗するため注意が必要です。
stack_base = 0x00000000
stack_size = 0x00100000
uc.mem_map(stack_base, stack_size)
uc.mem_write(stack_base, b"\x00" * stack_size)Code language: Python (python)次にEBPレジスタの初期値の設定を行います。今回はスタック領域の半分地点 (オフセット0x80000) をベースポインタとして指定しました。ここまで大きな領域を用意する必要はないので、気になる方はより小さいサイズのスタック領域を作成するとよいでしょう。
EBP = stack_base + (stack_size // 2)
uc.reg_write(UC_X86_REG_EBP, EBP)Code language: Python (python)ここまでのコードでスタック領域に値 (データ) を書き込む準備は整いました。今回のエミュレーション対象のコードでは、 EBP + 0xC (a2_strlen) からハッシュ化対象の文字列の長さを、 EBP + 0x10 (a3_seedval) からシード値を、 EBP - 0x48 (string) からハッシュ化対象の文字列を参照しています。以下のコードのように、それぞれのオフセットに対応する値 (データ) を書き込みましょう。
len_bytes = struct.pack('<I', len(string))
uc.mem_write(EBP + 0xC, len_bytes)
seed_bytes = struct.pack('<I', seed)
uc.mem_write(EBP + 0x10, seed_bytes)
uc.mem_write(EBP - 0x48, string)Code language: Python (python)最後に、EDIレジスタとESIレジスタに文字列の長さを格納しましょう。前出のコードでは参照箇所はありませんでしたが、ESIレジスタとEDIレジスタには文字列の長さがこのコードの実行時点で格納されており、周辺コードの実行に必要であったためそうしておきます。
uc.reg_write(UC_X86_REG_EDI, len(string))
uc.reg_write(UC_X86_REG_ESI, len(string))Code language: Python (python)これでエミュレーションを実行するために必要な準備は完了しました。先ほどの例と同様にコード領域の準備などを行った上で emu_start 関数を呼び出せば、ハッシュ値の算出処理をエミュレートできるはずです。
uc.emu_start(code_base, code_end, timeout=0, count=0)Code language: Python (python)ここまでの内容を1つの関数にまとめたコードを以下に示します。
HASHCODE_START = 0x1007030D
HASHCODE_END = 0x1007051E
def calculate_hash(string, seed=0xB801FCDA):
string = string.lower()
code = ida_bytes.get_bytes(HASHCODE_START, HASHCODE_END - HASHCODE_START)
uc = Uc(UC_ARCH_X86, UC_MODE_32)
stack_base = 0x00000000
stack_size = 0x00100000
uc.mem_map(stack_base, stack_size)
uc.mem_write(stack_base, b"\x00" * stack_size)
EBP = stack_base + (stack_size // 2)
uc.reg_write(UC_X86_REG_EBP, EBP)
len_bytes = struct.pack('<I', len(string))
uc.mem_write(EBP + 0xC, len_bytes)
seed_bytes = struct.pack('<I', seed)
uc.mem_write(EBP + 0x10, seed_bytes)
uc.mem_write(EBP - 0x48, string)
uc.reg_write(UC_X86_REG_EDI, len(string))
uc.reg_write(UC_X86_REG_ESI, len(string))
code_base = 0x00100000
code_size = 0x00100000
uc.mem_map(code_base, code_size, UC_PROT_ALL)
uc.mem_write(code_base, b"\x00" * code_size)
uc.mem_write(code_base, code)
uc.emu_start(code_base, code_base + len(code), timeout=0, count=0)
return uc.reg_read(UC_X86_REG_EAX)Code language: Python (python)この関数を定義して、calculate_hash(b'LoadLibraryA') のような関数呼び出しを行えば、 LoadLibraryA 関数のハッシュ値 0x439C7E33 を戻り値として得られます。実際に先述したローダーのコードを確認してみると、ハッシュ値を引数として渡して LoadLibraryA 関数のアドレスを取得しているコードを確認できます。
.text:1008E346 6A 04 push 4
.text:1008E348 68 33 7E 9C 43 push 439C7E33h
.text:1008E34D 6A 0F push 0Fh
.text:1008E34F 6A 00 push 0
.text:1008E351 E8 E4 98 FD FF call api_hashing_via_murmurhash2Code language: plaintext (plaintext)解析の効率化
ハッシュ化されたAPI関数名を復元する方法は準備できましたが、いちいちハッシュ値を確認して対応するAPI関数名を調べるのは効率的ではありません。このセクションでは、IDAPython APIを用いて逆アセンブル結果やデコンパイル結果に自動的にハッシュ値に対応するAPI関数名を表示する方法について解説します。なお、IDA Pro 9.1で実行されることを前提にスクリプトを作成しています。
まずはハッシュ値をキー、API関数名を値として持つ辞書型のデータを作成しましょう。今回のローダーでは kernel32.dll および ntdll.dll がエクスポートしている関数をAPI Hashingを用いて呼び出していたため、これらのDLLがエクスポートしている関数の名前のハッシュ値を計算すれば良いです。このような処理は pefile モジュールを使用すれば以下のように実装できます。
api_dict = {}
for dll in ['kernel32.dll', 'ntdll.dll']:
try:
pe = pefile.PE('C:\\Windows\\System32\\' + dll)
api_list = [e.name for e in pe.DIRECTORY_ENTRY_EXPORT.symbols]
api_list = [api for api in api_list if api != None]
except (AttributeError, pefile.PEFormatError):
continue
for api in api_list:
api_dict[calculate_hash(api)] = apiCode language: Python (python)次にローダー内で使用されているハッシュ値を取得する必要があります。今回はAPI hashing関数のアドレスをハッシュ値をもとに解決する関数の第三引数がハッシュ値となっていたため、逆アセンブル結果を解析してハッシュ値を取得するような処理を実装しました。
for xref in idautils.XrefsTo(API_RESOLVER_FN):
ea = xref.frm
push_cnt = 0
while ea != idc.BADADDR:
if idc.print_insn_mnem(ea) == 'push':
push_cnt += 1
if push_cnt == 3:
hash_value = idc.get_operand_value(ea, 0) & 0xFFFFFFFF
break
ea = idc.prev_head(ea)Code language: Python (python)最後に、IDAデータベース上にAPI関数名とハッシュ値が対応した列挙型を作成して、ハッシュ値を列挙型の名前で表示するように設定しましょう。
# Create enum type for API hash
enum = idc.get_enum(ENUM_NAME)
if enum == idc.BADADDR:
enum = idc.add_enum(idaapi.BADNODE, ENUM_NAME, idaapi.hex_flag())Code language: Python (python)# Add enum member and apply it
enum_value = idc.get_enum_member(enum, hash_value, 0, 0)
if enum_value == -1:
idc.add_enum_member(enum, ENUM_NAME + "_" + api_dict[hash_value].decode(), hash_value)
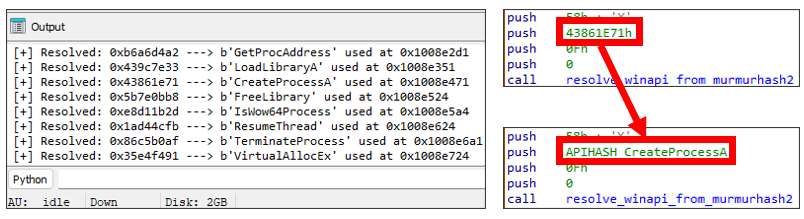
idc.op_enum(ea, 0, enum, 0)Code language: PHP (php)ここまで解説した内容を組み合わせたスクリプト4を実行すると図5のような結果が得られます。
スクリプトの全体像はAppendixに記載しています。
おわりに
UnicornはAPI Hashingの解析のほかにも、データの暗号化アルゴリズムやIndirect Callの解析など、マルウェア解析において幅広く活用することができます。IDAPythonのようなインターフェースと組み合わせるとマルウェア解析を大きく効率化することができるので、興味がある方はぜひ、学習および習得に挑戦してみてください。
Appendix: API Hashing解析用スクリプト ↩︎
from unicorn import *
from unicorn.x86_const import *
import idaapi
import idautils
import ida_funcs
import pefile
import struct
API_RESOLVER_FN = 0x10067C3A
HASHCODE_START = 0x1007030D
HASHCODE_END = 0x1007051E
ENUM_NAME = 'APIHASH'
def calculate_hash(string, seed=0xB801FCDA):
string = string.lower()
code = ida_bytes.get_bytes(HASHCODE_START, HASHCODE_END - HASHCODE_START)
uc = Uc(UC_ARCH_X86, UC_MODE_32)
stack_base = 0x00100000
stack_size = 0x00100000
EBP = stack_base + (stack_size // 2)
uc.mem_map(stack_base, stack_size)
uc.mem_write(stack_base, b"\x00" * stack_size)
uc.reg_write(UC_X86_REG_EDI, len(string))
uc.reg_write(UC_X86_REG_ESI, len(string))
len_bytes = struct.pack('<I', len(string))
uc.mem_write(EBP + 0xC, len_bytes)
seed_bytes = struct.pack('<I', seed)
uc.mem_write(EBP + 0x10, seed_bytes)
uc.mem_write(EBP - 0x48, string)
uc.reg_write(UC_X86_REG_EBP, EBP)
code_base = 0x00200000
code_size = 0x00100000
uc.mem_map(code_base, code_size, UC_PROT_ALL)
uc.mem_write(code_base, b"\x00" * code_size)
uc.mem_write(code_base, code)
code_end = code_base + len(code)
uc.emu_start(code_base, code_end, timeout=0, count=0)
return uc.reg_read(UC_X86_REG_EAX)
def main():
# Calculate hash value of API functions
api_dict = {}
for dll in ['kernel32.dll', 'ntdll.dll']:
try:
pe = pefile.PE('C:\\Windows\\System32\\' + dll)
api_list = [e.name for e in pe.DIRECTORY_ENTRY_EXPORT.symbols]
api_list = [api for api in api_list if api != None]
except (AttributeError, pefile.PEFormatError):
continue
for api in api_list:
api_dict[calculate_hash(api)] = api
# Create enum type for API hash
enum = idc.get_enum(ENUM_NAME)
if enum == idc.BADADDR:
enum = idc.add_enum(idaapi.BADNODE, ENUM_NAME, idaapi.hex_flag())
# Collect used API hash values
for xref in idautils.XrefsTo(API_RESOLVER_FN):
ea = xref.frm
push_cnt = 0
while ea != idc.BADADDR:
if idc.print_insn_mnem(ea) == 'push':
push_cnt += 1
if push_cnt == 3:
hash_value = idc.get_operand_value(ea, 0) & 0xFFFFFFFF
break
ea = idc.prev_head(ea)
# Print API hashing resolution result
if hash_value not in api_dict:
print(f'[-] Failed: {hex(hash_value)} used at {hex(xref.frm)}')
else:
print(f'[+] Resolved: {hex(hash_value)} ---> {api_dict[hash_value]} used at {hex(xref.frm)}')
# Add enum member and apply it
enum_value = idc.get_enum_member(enum, hash_value, 0, 0)
if enum_value == -1:
idc.add_enum_member(enum, ENUM_NAME + "_" + api_dict[hash_value].decode(), hash_value)
idc.op_enum(ea, 0, enum, 0)
if __name__ == '__main__':
main()Code language: Python (python)- MiasmはUnicornのようにエミュレーションに特化しておらず、汎用的なリバースエンジニアリングフレームワークとして設計されているため、単純な比較はできません。 ↩︎
- binarly-io/idalib – GitHub ↩︎
- この記事では取り扱いませんが、前述した通りC言語のプログラムからUnicornを利用することも可能です。興味がある方は公式サイトのチュートリアルを参考にするとよいでしょう。 ↩︎
- TorNetとPureHVNCを実行する新種のローダーの調査 のAppendix Bのスクリプトとほぼ同じ内容です。 ↩︎