Effective Malware Analysis using Unicorn
Unicorn is a QEMU-based CPU emulator framework presented at Black Hat USA 2015.
> GitHub – unicorn-engine/unicorn: Unicorn CPU emulator framework (ARM, AArch64, M68K, Mips, Sparc, PowerPC, RiscV, S390x, TriCore, X86)
https://github.com/unicorn-engine/unicorn
It is used for multiple purposes, such as malware analysis and fuzzing. Many binary analysts love it because it offers several advantages compared to other emulator frameworks. In this article, we will introduce the basics of Unicorn and use cases for malware analysis.
Features of Unicorn
In this section, we will introduce 3 features of Unicorn.
Multi-architecture Support
As of July 2025, Unicorn supports emulating 10 CPU architectures. As an example, another framework that supports CPU code emulation, Miasm supports only 5 CPU architectures1, so this is a significant advantage for Unicorn.
| ARM | ARM64 (ARMv8) | M68K | MIPS | PowerPC |
| RISCV | SPARC | S390X | TriCore | x86 (16, 32, 64bit) |
Even if you cannot prepare an execution environment for those architectures, you can use Unicorn to emulate their code.
Lightweight
Unicorn does not emulate operating system contexts such as system calls, so compared to other binary analysis frameworks it is lightweight. If you need higher layer emulation (I/O handling, emulation per executable, etc), you can use Qiling Framework, a Unicorn-based emulator framework.
Plentiful Bindings
Unicorn has official bindings for Python, C, Rust, .NET Framework, and more.
Recently, a Rust binding for the IDA SDK was released2, enabling you to develop programs that automate malware analysis with Unicorn using only IDA and Rust.
Unicorn × Malware Analysis
Utilizing its ability to execute CPU code virtually, malware analysts often use Unicorn to decrypt strings and data within malware and to remove obfuscation that affects control flow. Having been released about 10 years ago, Unicorn is a framework that is familiar even to beginners, as many use cases have been made publicly available. This article is one such example, but for reference, here are a few examples of how Unicorn is used in malware analysis:
- Decrypting BazarLoader strings with a Unicorn (Jason Reaves)
- Resolving Stack Strings with Capstone Disassembler & Unicorn in Python (0ffset Traning Solutions)
- ADVDeobfuscator.py (strazzere)
Unicorn 101
There are several ways to install Unicorn, such as compiling from source code or using a software repository, but this article will introduce the easiest method using pip. pip is a Python package management system, and installing Unicorn from pip will also install the Python binding of Unicorn3.
pip install unicornLet’s check whether Unicorn is installed correctly. Execute the following Python code in your environment.
from unicorn import *
from unicorn.x86_const import *
# MOV EAX,DEADBEEF
# INC EBX
code = bytes.fromhex('B8 EF BE AD DE 43')
# Initialize Unicorn to emulate 32-bit code of x86
uc = Uc(UC_ARCH_X86, UC_MODE_32)
# Map memory region and write the code
code_base = 0x00000000
code_size = 0x00100000
uc.mem_map(code_base, code_size, UC_PROT_ALL)
uc.mem_write(code_base, b"\x00" * code_size)
uc.mem_write(code_base, code)
code_end = code_base + len(code)
# Write value to EBX register
uc.reg_write(UC_X86_REG_EBX, 0x1000)
# Start emulation
uc.emu_start(code_base, code_end, timeout=0, count=0)
# Read and output value in EAX / EBX register
print(f'EAX = {hex(uc.reg_read(UC_X86_REG_EAX))}')
print(f'EBX = {hex(uc.reg_read(UC_X86_REG_EBX))}')Code language: Python (python)If Unicorn is working correctly, you should see the following result.
EAX = 0xdeadbeef
EBX = 0x1001From this point, we will explain the meaning of code within this Python script.
First, on lines 1-2, we import the required modules to access the Unicorn APIs. In addition to the module (unicorn), we also import a submodule called unicorn.x86_const, which contains constant values necessary for emulating x86 code. We import this here to simplify the subsequent code.
from unicorn import *
from unicorn.x86_const import *Code language: Python (python)On line 6, Unicorn stores the code to be emulated in the variable code. In this case, we have prepared x86 (32-bit) code that stores the value 0xDEADBEEF in the EAX register and increments the value of the EBX register.
# MOV EAX,DEADBEEF
# INC EBX
code = bytes.fromhex('B8 EF BE AD DE 43')Code language: Python (python)Next, on line 9, Unicorn is initialized so that x86 (32-bit) code can be executed. Here, we pass the constants UC_ARCH_X86 and UC_MODE_32 as initialization arguments. By passing UC_ARCH_X86 and UC_MODE_64, we can emulate x86 (64-bit) code, and by passing UC_ARCH_ARM and UC_MODE_THUMB, we can emulate ARM Thumb mode code.
# Initialize Unicorn to emulate 32-bit code of x86
uc = Uc(UC_ARCH_X86, UC_MODE_32)Code language: Python (python)Lines 12-17 map the code region (uc.mem_map) and write the code defined in line 5 (uc.mem_write) to it. In this case, the base address of the code region is set to 0x00000000, and the size is set to 0x00100000. The mapped region is zero-filled, and then the code within the code variable is written to it. In Unicorn, users must manually map and control the stack region and code region.
# Map memory region and write the code
code_base = 0x00000000
code_size = 0x00100000
uc.mem_map(code_base, code_size, UC_PROT_ALL)
uc.mem_write(code_base, b"\x00" * code_size)
uc.mem_write(code_base, code)Code language: Python (python)On line 20, the initial value 0x1000 is set in the EBX register. Since the code that increments the value of the EBX register is being emulated, if the emulation is executed normally, the value 0x1001 should be stored in the EBX register when execution is done.
# Write value to EBX register
uc.reg_write(UC_X86_REG_EBX, 0x1000)Code language: Python (python)On line 23, emulation is performed by Unicorn. Here, it is necessary to specify the start and end addresses of the code to be emulated. In this implementation, the start address is specified as the beginning of the code region, and the end address is specified as the start address plus the length of the code.
# Start emulation
uc.emu_start(code_base, code_base + len(code), timeout=0, count=0)Code language: Python (python)Finally, lines 26 and 27 read the values of the EAX and EBX registers and output them using the print function.
# Read and output value in EAX / EBX register
print(f'EAX = {hex(uc.reg_read(UC_X86_REG_EAX))}')
print(f'EBX = {hex(uc.reg_read(UC_X86_REG_EBX))}')Code language: Python (python)Analyzing API Hashing
API hashing is a method that dynamically resolves the address of an API function from a hashed function name and DLL name, generated using a chosen algorithm.

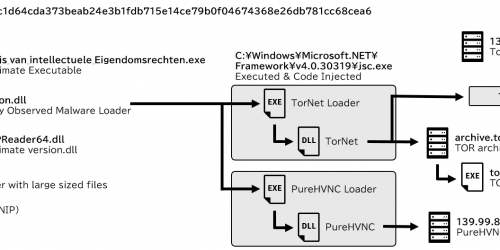
In this section, we will introduce a specific use case for analyzing a malware loader introduced in the article New Loader Executing TorNet and PureHVNC. This loader implemented API hashing using a distinctive algorithm called MurmurHash2.

In order to perform static analysis on malware that implements API hashing, it is important to obtain the implementation of the hash algorithm. However, if the malware uses a custom algorithm or a modified version of an existing algorithm, this can significantly increase the time required for static analysis and algorithm implementation. To address this, Unicorn can emulate the code segments responsible for calculating hash values within the malware. This allows analysts to calculate hash values based on API function names without needing to implement the hash algorithm itself, thereby enabling the analysis of API hashing.
Identify code of hash algorithm
First, we need to determine the range of code to be emulated by Unicorn. In most cases, the code for hash value calculation exists within an independent function, so we just need to find its function and emulate from the start address to the end address of the function. However, in this loader, junk code appeared both before and after the hash calculation code. Therefore, we had to determine the precise code range involved in the computation.

In this case, from offset 0x970D to 0x991E in loader was the code for hash value calculation.
.text:1007030D C7 45 A0 95 E9 D1 5B mov [ebp+var_60], 5BD1E995h
.text:10070314 C7 45 94 18 00 00 00 mov [ebp+var_6C], 18h
.text:1007031B 8B 45 0C mov eax, [ebp+a2_strlen]
.text:1007031E 89 45 88 mov [ebp+var_78], eax
.text:10070321 8D 45 B8 lea eax, [ebp+string]
.text:10070324 89 85 7C FF FF FF mov [ebp+var_84], eax
.text:1007032A 8B 45 10 mov eax, [ebp+a3_seedval]
.text:1007032D 89 85 70 FF FF FF mov [ebp+var_90], eax
<snip>
.text:100704F9 69 85 70 FF FF FF 95 imul eax, [ebp+var_90], 5BD1E995h
.text:100704F9 E9 D1 5B
.text:10070503 89 85 70 FF FF FF mov [ebp+var_90], eax
.text:10070509 8B 85 70 FF FF FF mov eax, [ebp+var_90]
.text:1007050F C1 E8 0F shr eax, 0Fh
.text:10070512 33 85 70 FF FF FF xor eax, [ebp+var_90]
.text:10070518 89 85 70 FF FF FF mov [ebp+var_90], eax
.text:1007051E 8B 85 70 FF FF FF mov eax, [ebp+var_90] ; Storing calculated hash value to EAX registerCode language: plaintext (plaintext)Run Emulation
As the disassembled code shows, this code obtains the string and length to be hashed by referencing local variables in the registers and stack. Therefore, it is necessary to write appropriate values (data) to the registers and stack before running the emulation.
First, we create the stack region. In the following code, we allocate a memory region of size 0x00100000, similar to when mapping the code region, and use it as the stack. At this point, it is important to note that if you mistakenly specify an address within the code region as the base address (starting address) of the stack region, or if the stack size is insufficient, the emulation will fail.
stack_base = 0x00000000
stack_size = 0x00100000
uc.mem_map(stack_base, stack_size)
uc.mem_write(stack_base, b"\x00" * stack_size)Code language: Python (python)Next, set the initial value of the EBP register. In this case, we specified the midpoint of the stack region (offset 0x80000) as the base pointer. Although the script creates a large stack region, a smaller region is sufficient for this sample.
EBP = stack_base + (stack_size // 2)
uc.reg_write(UC_X86_REG_EBP, EBP)Code language: Python (python)Now, let’s write the data values to the mapped stack region. In the code we are emulating, the string to be hashed is stored at EBP - 0x48 (string), its length at EBP + 0xC (a2_strlen), and the seed value at EBP + 0x10 (a3_seedval). As shown in the following code, write the corresponding values (data) to each offset.
len_bytes = struct.pack('<I', len(string))
uc.mem_write(EBP + 0xC, len_bytes)
seed_bytes = struct.pack('<I', seed)
uc.mem_write(EBP + 0x10, seed_bytes)
uc.mem_write(EBP - 0x48, string)Code language: Python (python)Finally, let’s store the length of the string in the EDI register and ESI register. Although the disassembled code shown above doesn’t reference them, they are used in the omitted code, making them necessary for execution.
uc.reg_write(UC_X86_REG_EDI, len(string))
uc.reg_write(UC_X86_REG_ESI, len(string))Code language: Python (python)Now we are ready to run the emulation. As in the former example, call the emu_start function after preparing the code region. We should be able to emulate code that calculates MurmurHash2 hash value.
uc.emu_start(code_base, code_end, timeout=0, count=0)Code language: Python (python)The code below summarizes the contents described so far into a single function.
HASHCODE_START = 0x1007030D
HASHCODE_END = 0x1007051E
def calculate_hash(string, seed=0xB801FCDA):
string = string.lower()
code = ida_bytes.get_bytes(HASHCODE_START, HASHCODE_END - HASHCODE_START)
uc = Uc(UC_ARCH_X86, UC_MODE_32)
stack_base = 0x00000000
stack_size = 0x00100000
uc.mem_map(stack_base, stack_size)
uc.mem_write(stack_base, b"\x00" * stack_size)
EBP = stack_base + (stack_size // 2)
uc.reg_write(UC_X86_REG_EBP, EBP)
len_bytes = struct.pack('<I', len(string))
uc.mem_write(EBP + 0xC, len_bytes)
seed_bytes = struct.pack('<I', seed)
uc.mem_write(EBP + 0x10, seed_bytes)
uc.mem_write(EBP - 0x48, string)
uc.reg_write(UC_X86_REG_EDI, len(string))
uc.reg_write(UC_X86_REG_ESI, len(string))
code_base = 0x00100000
code_size = 0x00100000
uc.mem_map(code_base, code_size, UC_PROT_ALL)
uc.mem_write(code_base, b"\x00" * code_size)
uc.mem_write(code_base, code)
uc.emu_start(code_base, code_base + len(code), timeout=0, count=0)
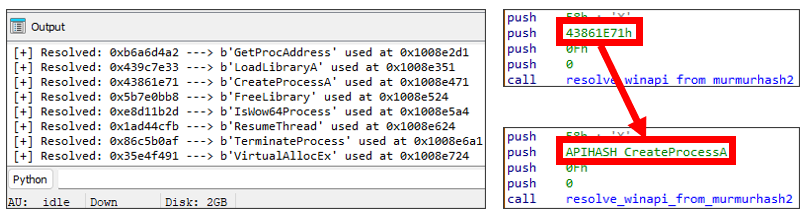
return uc.reg_read(UC_X86_REG_EAX)Code language: Python (python)After defining this function, if we call it by like calculate_hash(b'LoadLibraryA'), we can obtain hash value of LoadLibraryA function 0x439C7E33 as a return value. If we check the loader, we can find code that retrieves the function address of LoadLibraryA from its hash value.
.text:1008E346 6A 04 push 4
.text:1008E348 68 33 7E 9C 43 push 439C7E33h
.text:1008E34D 6A 0F push 0Fh
.text:1008E34F 6A 00 push 0
.text:1008E351 E8 E4 98 FD FF call api_hashing_via_murmurhash2Code language: plaintext (plaintext)Putting It All Together
Now, we can compute an API hash from its API name. However, to resolve API hashing in malware, we need a method to obtain the API name from a given hash, since malware using API hashing contains only hashes and we want to determine which APIs are called. In this section, we will explain how to use the IDAPython API to automatically display API function names corresponding to hash values in disassembly and decompilation results. Note that the script is designed to run on IDA Pro 9.1.
First, let’s create a dictionary-type data structure where the hash values are the keys and the API function names are the values. In this loader, the functions exported by kernel32.dll and ntdll.dll were called using API Hashing, so we only need to calculate the hash values of the function names exported by these DLLs. The following code implements this procedure using the pefile module.
api_dict = {}
for dll in ['kernel32.dll', 'ntdll.dll']:
try:
pe = pefile.PE('C:\\Windows\\System32\\' + dll)
api_list = [e.name for e in pe.DIRECTORY_ENTRY_EXPORT.symbols]
api_list = [api for api in api_list if api != None]
except (AttributeError, pefile.PEFormatError):
continue
for api in api_list:
api_dict[calculate_hash(api)] = apiCode language: Python (python)Next, we need to obtain the hash value used in the loader. In this case, since the third argument of the function that resolves the address of the API hashing function based on the hash value was the hash value itself. We implemented code to obtain the hash values by referring to the disassembled code that contains them.
for xref in idautils.XrefsTo(API_RESOLVER_FN):
ea = xref.frm
push_cnt = 0
while ea != idc.BADADDR:
if idc.print_insn_mnem(ea) == 'push':
push_cnt += 1
if push_cnt == 3:
hash_value = idc.get_operand_value(ea, 0) & 0xFFFFFFFF
break
ea = idc.prev_head(ea)Code language: Python (python)Finally, create an enumeration type with API function names and hash values, and make IDA display the hash values as enumeration names.
# Create enum type for API hash
enum = idc.get_enum(ENUM_NAME)
if enum == idc.BADADDR:
enum = idc.add_enum(idaapi.BADNODE, ENUM_NAME, idaapi.hex_flag())Code language: PHP (php)# Add enum member and apply it
enum_value = idc.get_enum_member(enum, hash_value, 0, 0)
if enum_value == -1:
idc.add_enum_member(enum, ENUM_NAME + "_" + api_dict[hash_value].decode(), hash_value)
idc.op_enum(ea, 0, enum, 0)Code language: Python (python)Executing the resulted script provides result like Figure 5.
Entire script is shown in Appendix4.
Conclusion
In addition to API hashing analysis, Unicorn can be widely used in malware analysis, such as analyzing data encryption algorithms and indirect calls. When combined with an interface such as IDAPython, it can greatly streamline malware analysis, so if you are interested, try learning and mastering it.
Appendix: API Hashing Resolver Script
from unicorn import *
from unicorn.x86_const import *
import idaapi
import idautils
import ida_funcs
import pefile
import struct
API_RESOLVER_FN = 0x10067C3A
HASHCODE_START = 0x1007030D
HASHCODE_END = 0x1007051E
ENUM_NAME = 'APIHASH'
def calculate_hash(string, seed=0xB801FCDA):
string = string.lower()
code = ida_bytes.get_bytes(HASHCODE_START, HASHCODE_END - HASHCODE_START)
uc = Uc(UC_ARCH_X86, UC_MODE_32)
stack_base = 0x00100000
stack_size = 0x00100000
EBP = stack_base + (stack_size // 2)
uc.mem_map(stack_base, stack_size)
uc.mem_write(stack_base, b"\x00" * stack_size)
uc.reg_write(UC_X86_REG_EDI, len(string))
uc.reg_write(UC_X86_REG_ESI, len(string))
len_bytes = struct.pack('<I', len(string))
uc.mem_write(EBP + 0xC, len_bytes)
seed_bytes = struct.pack('<I', seed)
uc.mem_write(EBP + 0x10, seed_bytes)
uc.mem_write(EBP - 0x48, string)
uc.reg_write(UC_X86_REG_EBP, EBP)
code_base = 0x00200000
code_size = 0x00100000
uc.mem_map(code_base, code_size, UC_PROT_ALL)
uc.mem_write(code_base, b"\x00" * code_size)
uc.mem_write(code_base, code)
code_end = code_base + len(code)
uc.emu_start(code_base, code_end, timeout=0, count=0)
return uc.reg_read(UC_X86_REG_EAX)
def main():
# Calculate hash value of API functions
api_dict = {}
for dll in ['kernel32.dll', 'ntdll.dll']:
try:
pe = pefile.PE('C:\\Windows\\System32\\' + dll)
api_list = [e.name for e in pe.DIRECTORY_ENTRY_EXPORT.symbols]
api_list = [api for api in api_list if api != None]
except (AttributeError, pefile.PEFormatError):
continue
for api in api_list:
api_dict[calculate_hash(api)] = api
# Create enum type for API hash
enum = idc.get_enum(ENUM_NAME)
if enum == idc.BADADDR:
enum = idc.add_enum(idaapi.BADNODE, ENUM_NAME, idaapi.hex_flag())
# Collect used API hash values
for xref in idautils.XrefsTo(API_RESOLVER_FN):
ea = xref.frm
push_cnt = 0
while ea != idc.BADADDR:
if idc.print_insn_mnem(ea) == 'push':
push_cnt += 1
if push_cnt == 3:
hash_value = idc.get_operand_value(ea, 0) & 0xFFFFFFFF
break
ea = idc.prev_head(ea)
# Print API hashing resolution result
if hash_value not in api_dict:
print(f'[-] Failed: {hex(hash_value)} used at {hex(xref.frm)}')
else:
print(f'[+] Resolved: {hex(hash_value)} ---> {api_dict[hash_value]} used at {hex(xref.frm)}')
# Add enum member and apply it
enum_value = idc.get_enum_member(enum, hash_value, 0, 0)
if enum_value == -1:
idc.add_enum_member(enum, ENUM_NAME + "_" + api_dict[hash_value].decode(), hash_value)
idc.op_enum(ea, 0, enum, 0)
if __name__ == '__main__':
main()Code language: Python (python)- Note that Miasm is not specialized in emulation like Unicorn, but is designed as a general-purpose reverse engineering framework, so a simple comparison is not possible. ↩︎
- binarly-io/idalib – GitHub ↩︎
- Although this article does not cover it, it is also possible to use Unicorn from a program written in C language. If you are interested, please refer to the tutorial on the Unicorn’s official website.
https://www.unicorn-engine.org/docs/tutorial.html ↩︎ - Script is mostly same as the one shown in article “New Loader Executing TorNet and PureHVNC“. ↩︎